Психическое здоровье в цифрах: анализ данных
Концепция
Психическое здоровье — это важная тема, которая затрагивает миллионы людей по всему миру. Анализ этих данных может помочь выявить закономерности и взаимосвязи между различными факторами (например, сном, социальной поддержкой) и уровнем депрессии или стресса. Это может быть полезно для разработки стратегий улучшения психического здоровья.
Источник данных
Я выбрала датасет «Anxiety and Depression Mental Health Factors» (Факторы психического здоровья: тревога и депрессия), который находится на платформе Kaggle:
https://www.kaggle.com/datasets/ak0212/anxiety-and-depression-mental-health-factors
Этот набор данных содержит информацию о различных факторах, влияющих на психическое здоровье, таких как возраст, пол, уровень образования, социальная поддержка, часы сна, уровень депрессии, уровень стресса и др.
Типы графиков
Для визуализации данных я выбрала следующие типы графиков:
Гистограммы — для анализа распределения уровней депрессии и стресса.
Столбчатые диаграммы — для сравнения средних значений уровня депрессии и стресса по полу.
Линейные графики — для анализа зависимости уровня депрессии от часов сна.
Круговые диаграммы — для визуализации распределения уровня образования среди участников.
Облака слов — для визуализации текстовых данных.
Этапы работы
Я начала с подготовки среды для работы. Для этого я установила все необходимые библиотеки: pandas для работы с данными, matplotlib и seaborn для визуализации, а также wordcloud для создания облаков слов. После установки я импортировал их в свой код.
Чтобы графики выглядели красиво и консистентно, я настроила стиль с помощью seaborn, выбрав минималистичный дизайн с зеленой палитрой. Это помогло мне сразу задать тон для всех будущих визуализаций.
Следующим шагом я загрузила данные из CSV-файла. Для этого я использовала функцию pd.read_csv (). Чтобы убедиться, что данные загрузились корректно, я вывела первые несколько строк с помощью data.head (). Это позволило мне быстро ознакомиться со структурой данных и понять, какие столбцы мне понадобятся для анализа.
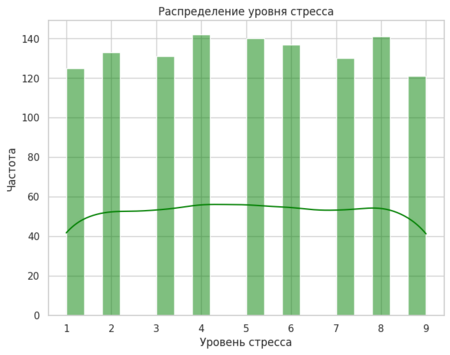
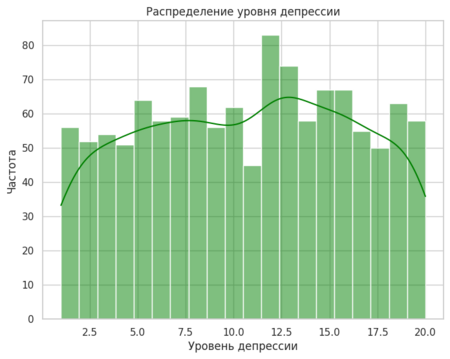
Визуализацию я начала с гистограмм, чтобы понять, как распределены уровни депрессии и стресса. Для этого я использовала sns.histplot (), добавив параметр kde=True, чтобы на графике отображалась кривая плотности. Это помогло мне увидеть, что большинство значений сосредоточено в определенном диапазоне.
Затем я решила исследовать зависимость уровня депрессии от часов сна. Для этого я построила линейный график с помощью sns.lineplot (). На графике я увидела, что с увеличением часов сна уровень депрессии снижается.


Чтобы сравнить уровни депрессии и стресса по полу, я создала две столбчатые диаграммы. Использовав sns.barplot (), я разместила их рядом друг с другом, чтобы было удобно сравнивать. Это помогло мне заметить, что у женщин уровень стресса в среднем выше, чем у мужчин.
Для визуализации распределения уровня образования я использовала круговую диаграмму. Сначала я подсчитала количество участников для каждого уровня образования с помощью value_counts (), а затем построила диаграмму с помощью plt.pie (). Это позволило мне быстро увидеть, какие уровни образования наиболее распространены.
Наконец, я решила добавить облака слов, чтобы визуализировать текстовые данные. Для этого я использовала библиотеку wordcloud. Я объединила текстовые данные в одну строку и создала облако слов. Это помогло мне увидеть, какие уровни образования и статусы занятости встречаются чаще всего.


Чтобы графики выглядели профессионально, я уделила внимание их стилизации. Я использовала зеленую палитру для всех графиков, чтобы сохранить единый стиль. Для облаков слов я выбрала минималистичный дизайн с белым фоном и зелеными словами, чтобы они гармонировали с остальными графиками.
На последнем этапе я сохранила все графики в формате PNG, чтобы их можно было использовать в презентации. Для этого я использовал функцию plt.savefig ()
Описание применения генеративной модели
Была применена генеративная модель https://chat.deepseek.com/ с целью генерации инструкций и рекомендаций по улучшению кода, а также для решения вопросов, связанных с правильным использованием функций, библиотек и других элементов программирования.



