
Концепция
В основе концепции проекта лежит стремление переосмыслить феномен «кавказского текста» в русской литературе Золотого века сквозь призму современных методов визуального анализа данных (Digital Humanities).
Выбор данной темы и корпуса текстов обусловлен глубоким исследовательским интересом к кавказскому региону и желанием предложить новый, структуралистский взгляд на наследие Михаила Лермонтова и Льва Толстого — авторов, которые лично участвовали в Кавказской войне в разные её периоды и зафиксировали полярные вехи в восприятии этого столкновения культур.
Цель инфографики — наглядно продемонстрировать эволюцию художественного языка их творчестве: от мистического лермонтовского романтизма до документального реализма Толстого.
Практическая польза проекта заключается в создании емкого визуального путеводителя по произведениям, который позволяет широкой аудитории мгновенно, без прочтения тысяч страниц, совершить экскурс в кавказский литературный контекст.
Исходные данные
Были выбраны литературные источники, такие как:
Электронная библиотека «Классика» (Библиотека Максима Мошкова): Основной источник верифицированных текстовых файлов произведений М. Ю. Лермонтова и Л. Н. Толстого в чистом формате .txt (раздел az.lib.ru).
Фундаментальная электронная библиотека «Русская литература и фольклор» (ФЭБ): Главный академический профильный ресурс для филологических исследований (feb-web.ru), использовавшийся для работы с каноническими текстами из полных собраний сочинений и авторитетными научными комментариями.
Электронная библиотека Института русской литературы (Пушкинского Дома) РАН: Ключевой первоисточник академических материалов, текстологических исследований кавказского текста и рукописного наследия авторов Золотого века (pushkinskijdom.ru).
Свободная электронная библиотека «Викитека» (Wikisource): Открытый ресурс, использовавшийся для сверки и кросс-аутентификации цифровых версий текстов русской классики (ru.wikisource.org).
Электронная энциклопедия «Википедия» (Wikipedia): Источник контекстных, библиографических и историко-биографических материалов по участию писателей в Кавказской войне и формированию «кавказского мифа» в культуре (ru.wikipedia.org).
Инфографика
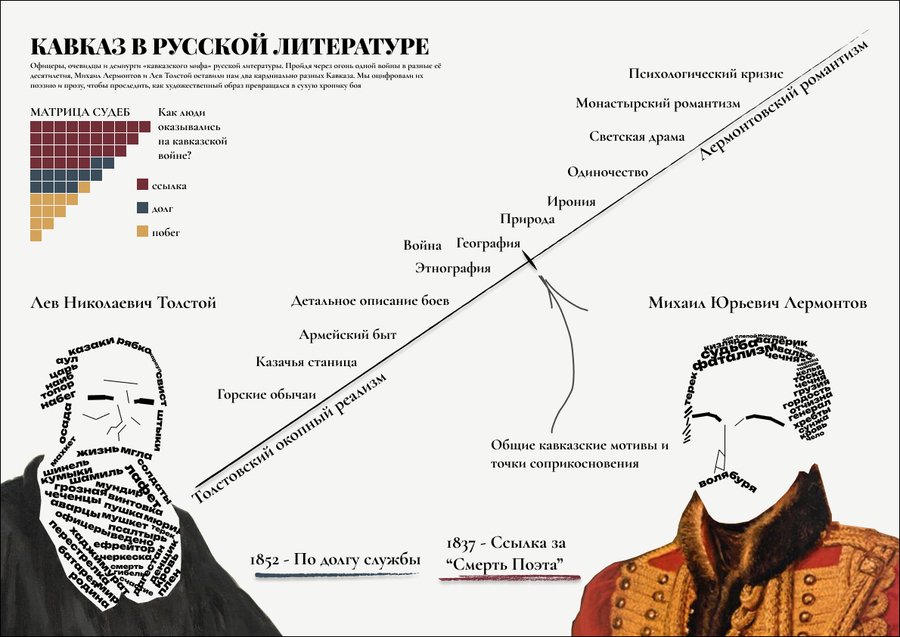
В данной инфографике представлены визуальные диаграммы в виде стилизованных портретов писателей. На них изображены самые главные слова, которые отражают суть их произведений и их взгляда на кавказские события. Не стоит путать их с самыми часто встречающимися словами (иначе это были бы одни союзы и предлоги), а те слова которые отражают общие настроения и суть произведения.
В центре разворота представлена ось Толстовский реализм-Лермонтовский Романтизм. Где в ходе анализа произведений писателей мы можем наблюдать где авторы имеют общие точки соприкосновения и общие кавказские мотивы и где они отдалены друг от друга в их восприятии Кавказа.
Мокапы
Процесс
- Процесс разработки данных и пайплайн производства.
Формирование аналитического массива данных проходило в рамках последовательного четырехэтапного пайплайна:
Этап 1: Сбор и препроцессинг данных. На первоначальном этапе текстовые массивы исследуемых произведений были извлечены из открытых верифицированных электронных библиотек и конвертированы в унифицированный текстовый формат (.txt) с очисткой от служебной разметки, метаданных и сторонних комментариев.
Этап 2: Контекстуальный и семантический анализ.
Для первичного семантического картирования и выявления сквозных макромотивов (таких как фатализм, мотив плена, быт горцев и психология войны) использовались методы глубокого текстуального анализа. Тексты были векторизованы в рамках ИИ-систем для выявления латентных смысловых связей и триггерных цитат.
Этап 3: Математический контент-анализ.
С целью исключения субъективности филологической оценки был применен метод жесткого квантитативного (количественного) анализа текста (Data Mining). С помощью специализированных программных скриптов на языке Python (с использованием библиотек для лемматизации и токенизации) был произведен точный подсчет абсолютной частоты встречаемости кавказских лексем. Из финальных частотных словарей был отсеян «лексический шум» (стоп-слова, предлоги, союзы и общеупотребительные глаголы).
- Используемые инструменты ИИ и программное обеспечение.
NotebookLM (Google): Применялся в качестве специализированного ИИ-контекстного блокнота для работы со строго локальными источниками. Инструмент использовался для верификации цитат, точечного поиска мотивов и извлечения смысловых концептов.
Gemini 3 / Advanced (Google): Использовался как большая языковая модель с расширенным окном контекста для первичной категоризации лексических пластов, анализа макроструктуры текстов и сопоставления полярных авторских экосистем (романтизма и реализма).
Python (скрипты контент-анализа): Использовался для математически точного частотного анализа, лемматизации слов (приведения к начальной форме) и создания финальных таблиц распределения весов лексем для инфографики.


