
1 // Идея проекта:
Во время выполнения домашних работ по курсу «Создание инфраструктуры креативного производства инструментами ИИ», я уделяла много времени тому, что встречает каждого студента или преподавателя по утрам перед началом занятий, сопровождает на обеденном перерыве, провожает домой и вечером помогает настроиться на подготовку к следующему дню — кофе. В современном мире вокруг этого напитка сложилась целая культура: кофейни разделились на несколько «волн», стали пространствами быстрых утренних ритуалов и местами почти медитативного созерцания, где чашка кофе становится поводом остановиться и внимательно посмотреть на повседневность.
В рамках проекта я рассматриваю кофе как форму «малого искусства». Латте-арт, появляющийся на поверхности напитка всего на несколько минут, превращает обычную чашку в кратковременное художественное высказывание.
Обучая нейросеть создавать изображения в духе ренессансной живописи (на основе работ непревзойденного мастера, Микеланджело Буонарроти), но интерпретированные как латте-арт на кофейной пене, я исследую, как искусственный интеллект может соединять высокую художественную традицию с повседневной визуальной культурой современной кофейни.
2 // Описание процесса обучения:
Процесс обучения генеративной сети делится на несколько этапов:
1 // Создание и подготовка (изменение размера) датасета изображений; 2 // Генерация текстового датасета (BLIP-подписей) на основе полученного датасет; 3 // Непосредственное обучение на основе установленных заранее библиотек; 4 // Воспроизведение нейросетью инструкций-промптов, результат обучения.
Каждый этап предполагает свой инструмент для работы, в проекте использовались такие ПО, как:
1 // Google Colab (среда выполнения);
2 // Stable Diffusion (обучение);
3 // Hugging Face (токен для обучения, загрузка модели на сайт);
4 // Chat GPT (помощь при написании кода);
5 // Adobe Illustrator (постобработка результатов скриншотов кода).
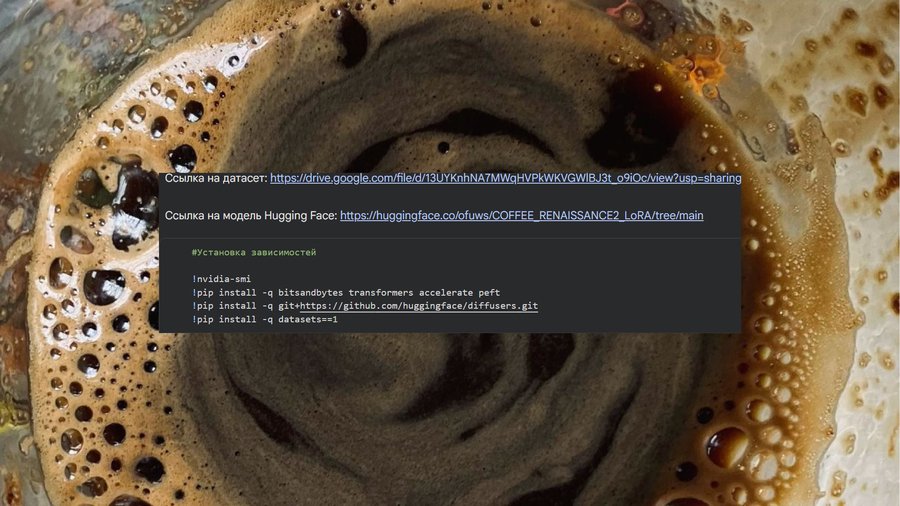
Установка зависимостей.
2.1 // Работа с датасетом изображений
Следующим этапом работы стала подготовка датасета и формирование текстовых описаний для изображений. Для этого архив с исходными изображениями был автоматически распакован, после чего каждый файл прошёл предварительную обработку: изображения приводились к единому квадратному формату, центрировались на нейтральном фоне и масштабировались до размера 512×512 пикселей, что обеспечивает корректную работу модели при обучении.
Далее была выполнена визуальная проверка части датасета для контроля качества подготовки изображений. Чтобы связать визуальные данные с текстовыми описаниями, использовалась модель автоматического описания изображений BLIP, которая генерировала подписи для каждого файла.
К полученным описаниям добавлялся стилистический префикс, задающий художественное направление проекта — COFFEE_RENAISSANCE, после чего все данные сохранялись в файл metadata.jsonl, используемый для последующего обучения модели.
Подготовка датасета, работа с архивом, путь к нему и распаковка.
Визуализация датасета.
Генерация подписей через BLIP.
2.2 // Непосредственный процесс обучения
После подготовки датасета следующим этапом стало обучение модели. Перед запуском обучения была выполнена очистка памяти среды и подключение к платформе Hugging Face для дальнейшего хранения и публикации результатов.
Затем изображения датасета были перемещены в отдельную директорию, предназначенную для обучения, после чего был запущен скрипт DreamBooth с использованием технологии LoRA на базе модели Stable Diffusion XL. В процессе обучения модель постепенно адаптировалась к заданному визуальному направлению — COFFEE_RENAISSANCE, учась воспроизводить характерное сочетание ренессансной живописной эстетики и визуального языка латте-арта.
После завершения обучения полученная LoRA-модель была сохранена, загружена в репозиторий Hugging Face и снабжена карточкой модели.
На финальном этапе была выполнена инициализация пайплайна генерации изображений и проверка работоспособности обученной модели, что подтвердило возможность использовать её для дальнейшей генерации изображений в разработанном художественном стиле.
Подключение Hugging Face.
Сам процесс обучения.
Входная директория, импорт модулей, работа с репозиторием.
Продолжение работы с Hugging Face, проверка работы модели.
3 // Серия изображений, итог генерации
После завершения обучения начался этап генерации изображений по различным текстовым промптам. В ходе своеобразных «экспериментов» стало заметно, что модель значительно лучше справляется с изображением людей (пар, мужчин, женщин), тогда как животные получаются менее убедительно (кот, птица).
Это объясняется особенностями обучающего материала: значительная часть визуальных референсов является работами, в которых центральное место занимает человеческая фигура. Таким образом, структура и содержание исходной базы данных напрямую влияют на характер генерации — нейросеть точнее воспроизводит те формы и сюжеты, которые чаще встречались в обучающем наборе изображений.
3.1 // Люди
3.1.1 // Мужчина


Первые пробные генерации, максимальное сходство с работами Микеланджело.
Промпт для изображений выше: prompt = ( «painting in COFFEE_RENAISSANCE style,» «renaissance man portrait inspired by Michelangelo fresco,» «dramatic anatomy, classical sculpture lighting, muscular male figure,» «latte art foam drawing on coffee surface, creamy milk foam illustration,» «coffee shop aesthetic, sepia coffee tones, delicate foam lines» )
Промпт для изображения ниже: prompt = ( «COFFEE_RENAISSANCE style, latte art of Michelangelo’s David,» «drawing on coffee foam inside a cappuccino cup, top-down view, delicate foam lines» )
Финальная генерация мужчины, наиболее удачная благодаря наличию кофейной кружки и стороннего латте-арта.
3.1.2 // Женщина


Первые генерации женщин, более точные благодаря тому, что во многом я основывалась на удачную генерацию с мужской фигурой.
Промпт для изображений выше: prompt = ( «painting in COFFEE_RENAISSANCE style,» «single renaissance woman portrait inspired by Michelangelo fresco,» «one woman, classical beauty, soft renaissance lighting,» «latte art foam drawing inside a coffee cup,» «top view cappuccino, coffee crema surface,» «milk foam illustration forming a female face,» «delicate barista latte art lines, warm coffee tones» )
Промпт для изображения ниже: prompt = ( «COFFEE_RENAISSANCE style, latte art portrait of Madonna on coffee foam,» «inside a cappuccino cup, top-down view, visible cup rim and handle, delicate foam lines, warm coffee tones» )
Финальная генерация женщины, наиболее удачная и реалистичная.
Промпт для изображений ниже: prompt = ( «COFFEE_RENAISSANCE style, latte art portrait of Venus on coffee foam,» «inside a cappuccino cup, top-down view, visible cup rim and handle,» «delicate foam lines forming Venus, warm coffee tones, cozy cafe aesthetic» )


Менее удачные генерации, не думаю, что подобное изображение было бы возможно воссоздать.
3.1.3 // Пара


Одни из самых неудачных генераций людей, любое усложнение сюжета негативно сказывалось на финальном результате.
3.1.4 // Ангел
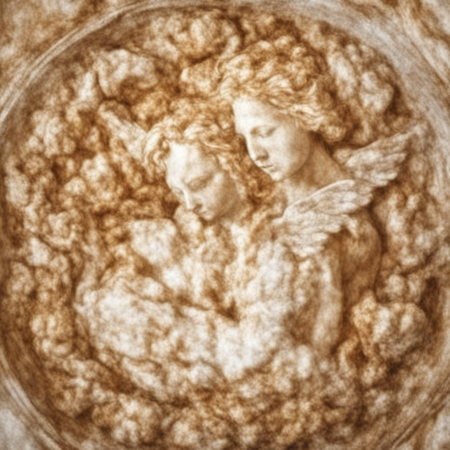

Достаточно правдоподобные генерации, впрочем, пришлось отказаться от изображения чашки и окружения, чтобы добиться более сложного сюжета.
3.2 // Животные
3.2.1 // Кот
Самые странные генерации относились к запросам о кошках (наиболее популярный сложный рисунок для латте-арта и наименее характерный для датасета персонаж).
3.2.2 // Птица


Крайне неудачные, впрочем, очень забавные генерации по запросам, связанным с птицей.
При этом наличие отдельных изображений птиц в датасете всё же оказало заметное влияние на результаты генерации: модель сравнительно легче воспроизводила птиц. В то же время изображения кошек получались значительно менее убедительными — вероятно, из-за того, что подобные объекты практически не встречались в исходном наборе данных. Этот эксперимент ещё раз показывает, насколько сильно состав датасета определяет визуальные возможности модели и диапазон объектов, которые она способна интерпретировать.
От наиболее к наименее реалистичной генерации по запросу «птица/голубь».



